Large scale cardinality calculations with probabilistic data structures in Scala
This is the second part of the article about aggregations on large scale datasets in Scala. If you didn’t read the first part I strongly encourage you to do so as I will continue on several thoughts and code examples from there.
Cardinality aggregation
One of the aggregations I’ve built last time is the number of unique elements in the impression log. The naive version from the last article:
object Unique extends Aggregateable[Seq[String], Long, Set[String]] {
def init = Set.empty[String]
def lift(in: Seq[String]): Set[String] = in.toSet
def combine(left: Set[String], right: Set[String]): Set[String] =
left ++ right
def unwrap(result: Set[String]): Long = result.size
}and used as
val res = Source(() => file.getLines)
.grouped(10000)
.runFold(new Aggregator(Unique)) { _ add _ }calculated cardinality of 9801125 from 39.1M dataset in about 79.8s.
—
Now lets have a look at the memory. Just to clarify, our cookie id is 128-bit UUID value.

Ouch.
As you can see on the chart our algorithm is quite memory hungry. At the peak we got to ~2.8GB of used heap memory and we calculated “only” ~39.1M impressions. Now, imagine we have 1B. I think its fair assumption to expect that memory needed for the calculation is linear to the number of true unique values in the dataset — 2x increase of unique values will need about 2x more memory because the values need to be all present in the Storage set at the point before we fetch the result cardinality value.
Approximations, is that ok?
There are certainly markets, where you need exact numbers, but fortunately, in advertising we are able to get away with small amount of error (in the end cookies are far from 100% accurate anyway). It turns out there is convenient algorithm exactly for this purpose called HyperLogLog.
HyperLogLog is an algorithm for the count-distinct problem, approximating the number of distinct elements in a set. I wouldn’t spend too much effort explaining it in the detail — see this post if you’re interested — , but let me elaborate on few particularly interesting attributes of HLL.
- You can construct empty HyperLogLog, which contains zero unique values
- You can combine 2 HyperLogLogs and get the combined cardinality approximation (order of combinations doesn’t matter)
Given these 2 attributes the HyperLogLog is a Monoid and will fit our Aggregateable interface nicely. Lets have a look.
object HLL extends Aggregateable[Seq[String], Long, HLLCounter] {
def init = new HLLCounter(true)
def lift(in: Seq[String]): HLLCounter = {
val hll = init
hll.put(in: _*)
hll
}
def combine(left: HLLCounter, right: HLLCounter): HLLCounter = {
val hll = init
hll.combine(left)
hll.combine(right)
hll
}
def unwrap(result: HLLCounter): Long = result.size
}Again, I am accepting Seq[String] as input and producing Long — number of unique values as an output. I am using com.adroll.cantor.HLLCounter — Java implementation of HyperLogLog — as a Storage. Note that I was able to use lift and combine methods to make our final aggregator immutable.
Using it is very simple. I just change one line in my current code:
val res = Source(() => file.getLines)
.grouped(10000)
.runFold(new Aggregator(HLL)) { _ add _ }Boom! I am calculating number of unique values in a set of 39.1M lines very efficiently. I got 9810035 uniques at 55.4s, which is about ~30% faster. Lets calculate an error: 9801125 / 9810035 = 0.9990917464. So we are 99.9% accurate. Quite good, isn’t it? And that’s not the main thing. Look at the memory consumption now:
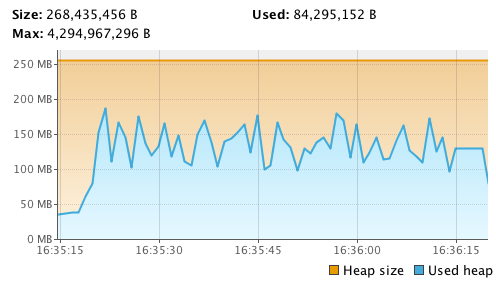
We got away with ~180MB of memory! Its because everything is streamed, (beyond 10k UUIDs grouping, which is in my control) there is no buffering and no need to load everything into the memory. HyperLogLog itself consumes about 1.5kb which is negligible. I bet we can get even further, but the above is already just fine as if I scale the dataset to 1B with this solution not much, if anything, will change.
Conclusions
As you could see we were able to gain significant speedup and massive improvement in the resource consumption on our distinct count problem with the sacrifice of as little as 0.1% of accuracy. Now, that might not be ok for some use cases, but think about it next time, when you’re tasked to do a distinct count of anything. You know the cost of 100% accuracy. Is it really what you need?
